近日,北京大学心理与认知科学学院李圭泉课题组在AI & SOCIETY在线发表题为“Unveiling trust in AI: the interplay of antecedents, consequences, and cultural dynamics”的系统综述论文。研究遵循PRISMA流程,跨计算机科学、信息管理、市场营销、管理与心理学等多学科领域,最终纳入562项定量实证研究,围绕“前因—中介/调节—结果”构建AI信任机制链路图,并在全球范围与中美对比两个层面揭示文化情境如何重塑信任形成与行为后果的传导路径。
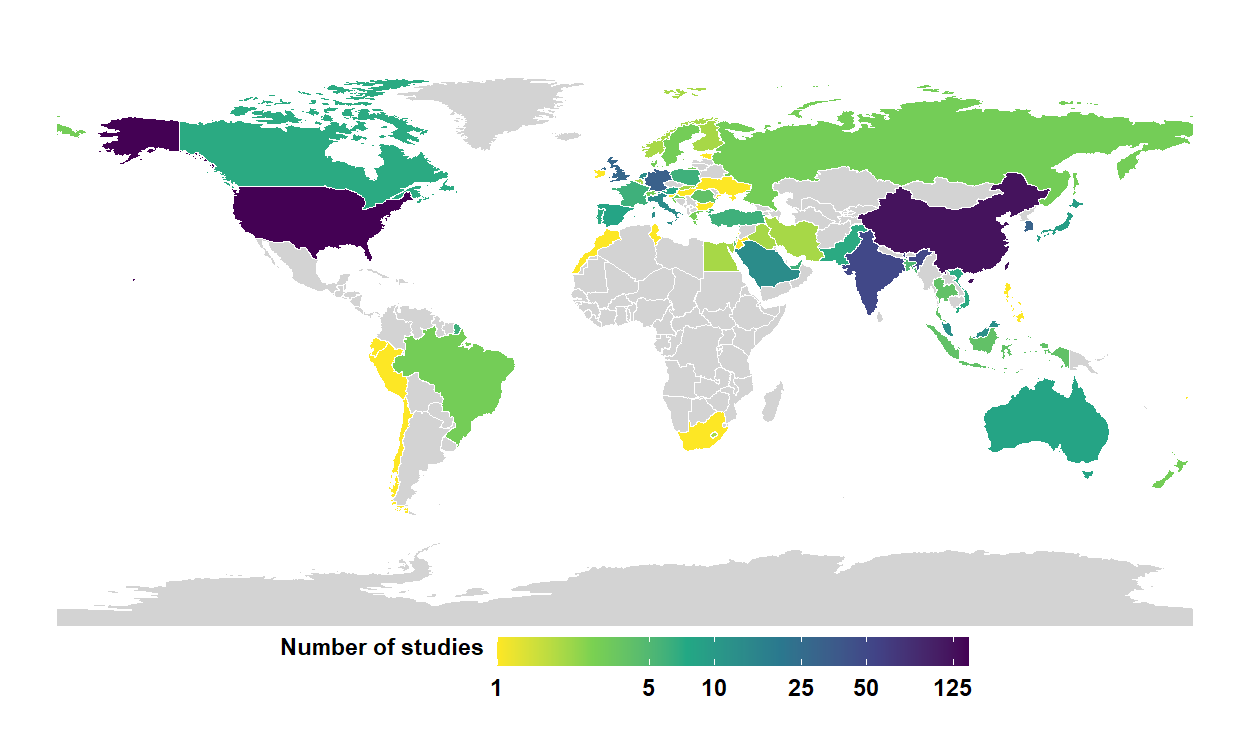
图1 按参与者所在国家汇总已纳入研究数量。
研究显示,能力、拟人化、个体因素、可解释性、隐私风险、人格特质、易用性、透明度、交互质量、社会影响、有用性、AI个性化、经验、公平、问责、(技术)不适感、态度、收益、努力期望与伦理等,是被反复验证的重要前因。在结果方面,信任最稳健地预测行为意向,并与态度、感知有用性、接受度、满意度、实际使用、投入度和信息披露等变量。跨文化比较显示:在美国样本中“个体因素”对信任的影响最强,而在中国样本中“能力”因素位居首位,提示不同文化取向会改变人们对“功能/能力”与“解释/透明”等线索的权重配置。
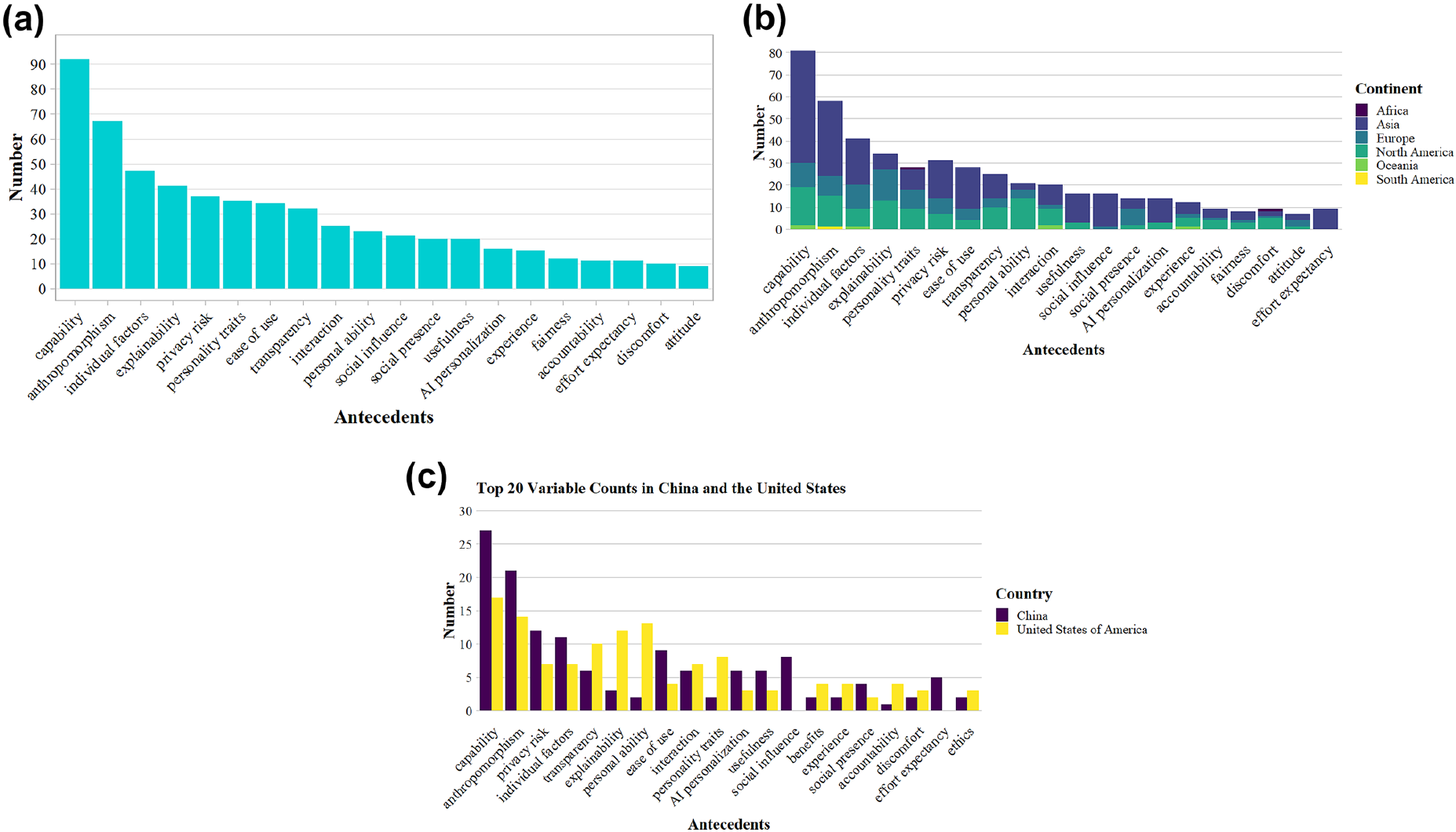
图2 a) 在全部研究中最常被报告的影响人对AI的信任的显著前因;b) 不同大洲中人对AI的信任之显著前因的分布;c) 中美样本中最常被报告的显著前因对比
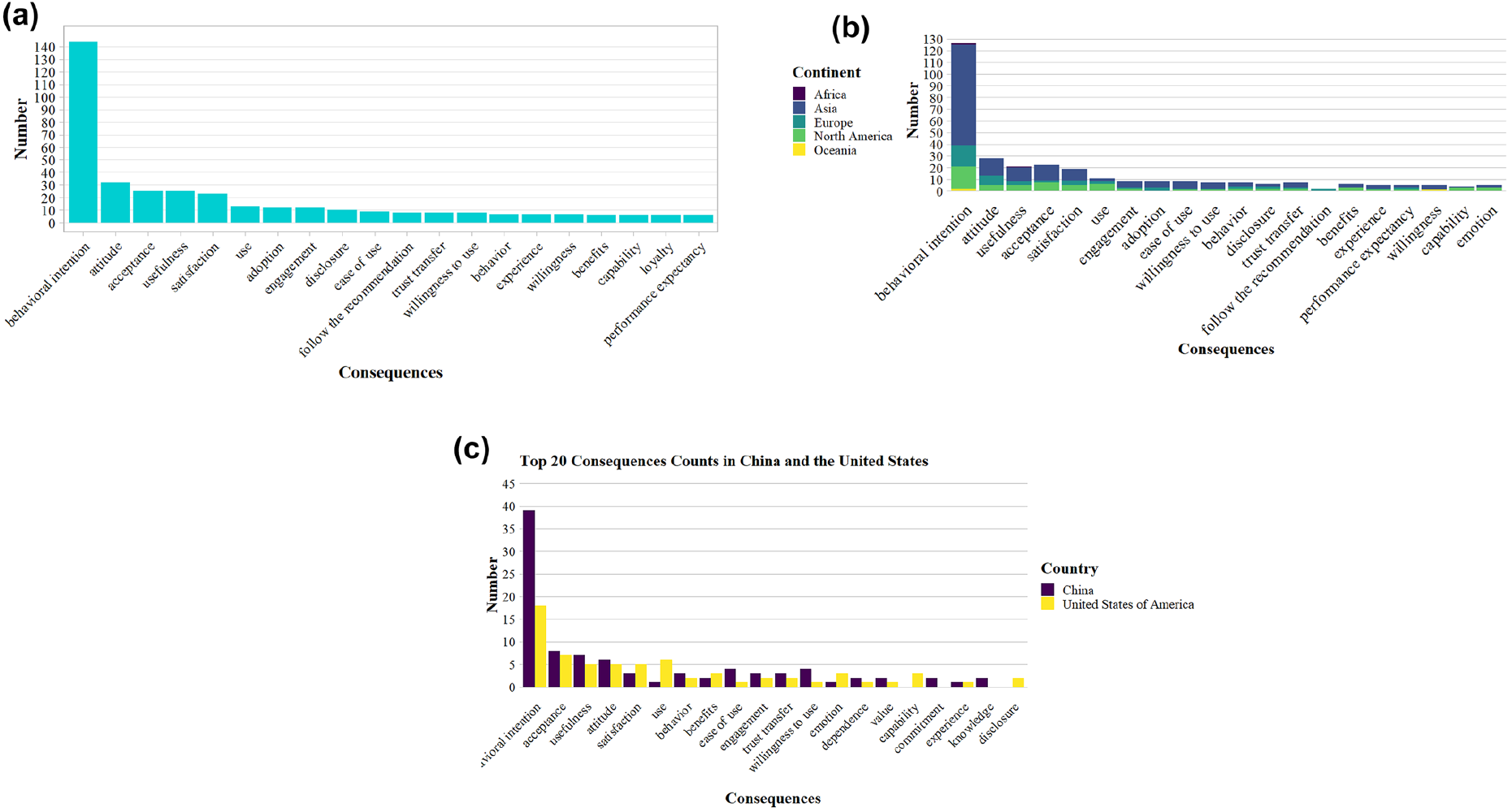
图3 a) 在全部研究中最常被报告的人对AI的信任之显著结果;b) 不同大洲中人对 AI 的信任之显著结果的分布;c) 中美样本中最常被报告的显著结果对比
研究发现,不同文化价值取向会改变人们对“功能/能力”与“解释/透明”等线索的权重配置:在强调个人自主与可控性的语境中,透明度与可解释性更能提升信任;在关系导向更强的语境中,能力、服务拟人化与情境匹配对信任的推动更显著。研究进一步绘制全球初始AI信任地图,呈现各国整体态度的差异分布,并提出“文化调节的AI信任框架”,强调信任的动态演化与“信任校准”的必要性,即通过真实性能反馈、误差管理与闭环沟通,避免“过度信任/不足信任”的双重风险。
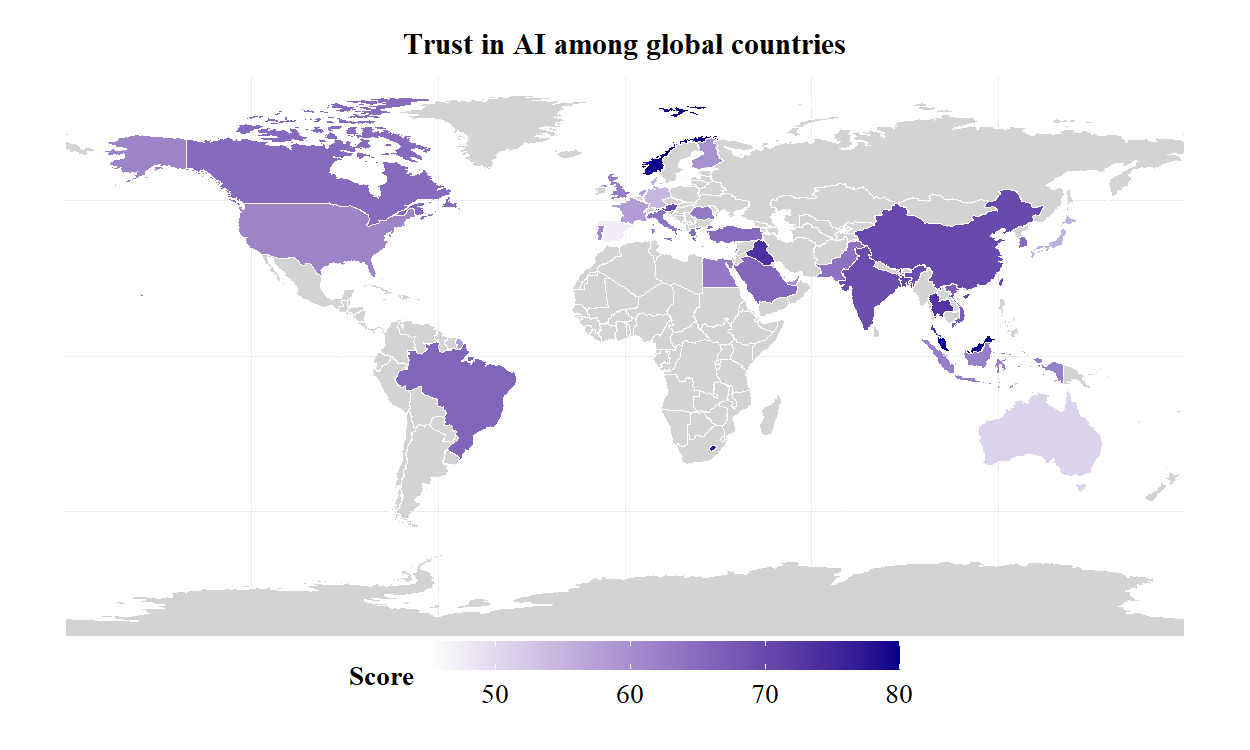
图4 全球各国的AI初始信任得分
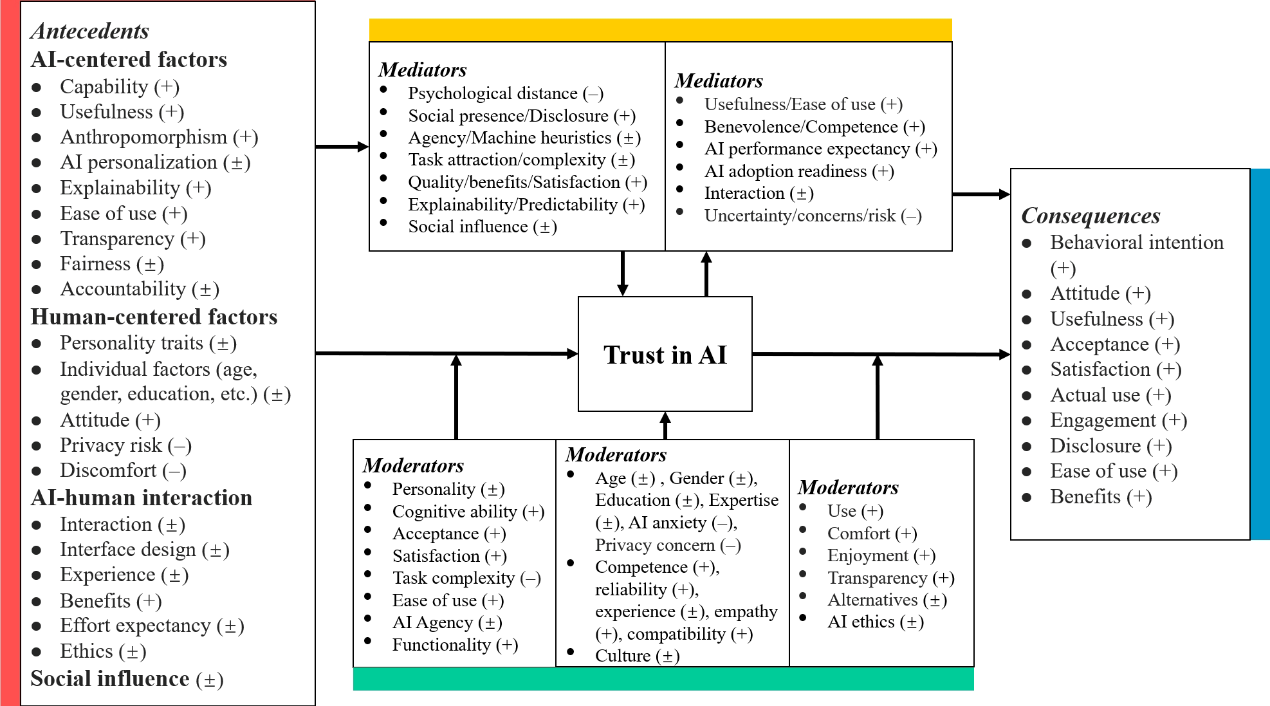
图5 AI的信任研究中四个关键主题领域之间关联的概览
该研究在理论上以跨学科与跨文化的证据,深化了“AI信任为何因情境而异”的解释力,并为后续关于动态信任、人与AI的互惠性信任与情境适配提供了统一框架;在实践上为高风险场景(医疗、金融、司法等)的可信AI建设提供了优先级建议:一是夯实能力、透明、可解释、公平与问责等“可信度基建”;二是推进“文化自适应设计”,在不同文化与行业语境中精准配置“透明/可控—拟人/社存—个性化/情境匹配”的组合;三是建立持续的信任校准与反馈闭环,动态维护恰当的信任水平,促进负责任的AI采纳。
本文第一作者为李圭泉课题组2023级博士生党钦普,通讯作者为李圭泉研究员。研究得到了国家自然科学基金(32471129, 71972109)的支持。
Dang, Q., & Li, G. (2025). Unveiling trust in AI: The interplay of antecedents, consequences, and cultural dynamics. AI & SOCIETY, 1-24.
https://link.springer.com/article/10.1007/s00146-025-02477-6
2025-09-26